Het ontstaan van de Indo-Europese taalfamilie.
Op zoek naar verwantschap, uit Onze Taal, maandblad van het Genootschap Onze TaalHoe vind je familieverbanden tussen talen?
Door Berthold van Maris
We spreken vaak over talen alsof het levende wezens zijn. Er zijn dode talen en levende talen. Net als dieren en planten kunnen talen met elkaar concurreren, een taal kan een andere taal verdringen en daardoor kan die andere taal zelfs uitsterven. Talen kunnen ook familie van elkaar zijn. Nabije familie, zoals het Nederlands en het Duits, of verre familie, zoals het Nederlands en het Latijn.
Die vergelijking met levende organismen gaat natuurlijk niet helemaal op, want talen hebben geen DNA. Maar de eigenschappen van talen kun je wel, als je dat wilt, in DNA-achtige codes weergeven, en op die codes kun je vervolgens de ingenieuze statistische methoden van de evolutionaire biologie loslaten. Je kunt de computer opdracht geven om op basis van die gegevens een stamboom van talen te berekenen die daar het best bij past.
Nullen en enen
Dat berekenen van een stamboom gaat als volgt. Je neemt een heleboel talen waarvan je vermoedt dat ze met elkaar verwant zijn. Je stelt honderdvijftig grammaticale vragen aan elk van die talen: of een bepaalde klank in die taal voorkomt, of het werkwoord een aparte meervoudsvorm heeft, of die taal veel met voorzetsels werkt, enzovoort. De antwoorden, 'ja' of 'nee', geefje weer als nullen en enen. Dat resulteert voor iedere taal in een reeks van honderdvijftig nullen en enen: een 'grammaticaal profiel', dat wel een beetje lijkt op een DNA-profiel. Talen die nauw verwant zijn, zullen grotendeels overlappende profielen hebben. Talen die verre familie van elkaar zijn, zullen grammaticale eigenschappen hebben die wat minder met elkaar overlappen.
Een van de pioniers op dit gebied is Michael Dunn, van het Max Planck Instituut in Nijmegen. Dunn is gespecialiseerd in talen en taalfamilies die aan de andere kant van de aardbol voorkomen: in Nieuw-Guinea en Australië. De Papoea's en de Aboriginals, die voor een deel nog in kleine groepen wonen, zijn samen goed voor meer dan duizend verschillende talen. Elk daarvan heeft een paar honderd tot een paar duizend sprekers.
In hoeverre al die talen aan elkaar verwant zijn, is nog een onopgehelderde kwestie. Michael Dunn heeft nu met behulp van de computer een eerste globale indeling in taalfamilies gemaakt. Hij deed dat op basis van grammaticale profielen voor honderdtwintig talen uit Nieuw-Guinea, Australië en het gebied daaromheen.
Oertaal
"Het maken van die profielen was veel werk", zegt Dunn. "Je stelt eerst een lijst samen van relevante grammaticale kenmerken. Die laat je voor iedere taal invullen door een specialist. Idealiter vraag je nog iemand anders om dat te checken. Per taal is dat één dag à één week werk."
Na twee, drie jaar waren al die profielen klaar en kon de computer ermee aan de slag. Welke talen staan dichter bij elkaar? Welke staan verder van elkaar af? Welke talen stammen vermoedelijk af van dezelfde 'proto-taal' of 'oertaal' (zoals Duits en Nederlands allebei afstammen van hetzelfde West-Germaans, dat tweeduizend jaar geleden werd gesproken)? En hoe kun je dat allemaal mooi combineren in een stamboom van talen die zich in de loop der tijd steeds verder uitsplitst?
"De computer was daar een paar weken mee bezig", zegt Dunn. "Het programma gaat op zoek naar de stamboom die het best past bij die data."
De computeranalyse liet zien dat die honderdtwintig talen uit Nieuw-Guinea en Australië kunnen worden onderverdeeld in negen groepen: zeven duidelijk omlijnde taalfamilies, daarnaast een grote groep talen in Nieuw-Guinea die moeilijk te plaatsen is, en tot slot nog een groep van talen die duidelijk kenmerken van twee taalfamilies met elkaar combineren, wat een gevolg kan zijn van vermenging door langdurig contact met andere talen.
Dunn: "Die stamboom kun je vervolgens weer vergelijken met wat er al eerder volgens de traditionele methode is gevonden."
Woordenschat
De traditionele methode werkt heel anders. Die is niet gebaseerd op grammaticale overeenkomsten, maar op overeenkomsten in de woordenschat. Sinds de negentiende eeuw is er overal in de wereld, in honderden talen en tientallen taalfamilies, gezocht naar 'cognaten': woorden die op elkaar lijken doordat ze afstammen van hetzelfde woord uit een vroegere taal (de 'proto-taal'). Dat is een enorm gepuzzel. De woorden vijf en cinq bijvoorbeeld stammen, hoe verschillend ze ook klinken, af van hetzelfde 'Indo-Europese' oerwoord (proto-woord). Daar kom je alleen achter door ze te vergelijken met woorden voor 'vijf' in een heleboel andere Indo-Europese talen.
De taalwetenschap heeft een methode ontwikkeld om vanuit al die nu bestaande vormen als het ware 'terug te rekenen' naar zo'n proto-woord. Het Indo-Europese oerwoord voor 'vijf' is bijvoorbeeld gereconstrueerd als 'penkwe'. Vijf en cinq stammen dus af van 'penkwe'.
Als je eenmaal een heleboel cognaten hebt gevonden, kun je daar trouwens ook op een moderne manier, met de computer dus, mee aan de gang gaan. Dunn: "Je kunt voor iedere taal turven welke cognaten nog wel, of niet meer, in die taal aanwezig zijn. Niet aanwezig resulteert in een nul, wel aanwezig in een één. Zo krijg je ook weer voor iedere taal een reeks van nullen en enen, die je door de computer kunt laten vergelijken. Ook daar rolt een meest waarschijnlijke stamboom uit."
Veranderingen
De methode die niet woorden maar grammaticale profielen met elkaar vergelijkt, werd in 2005 door Dunn geïntroduceerd. Veel taalkundigen hoopten dat ze hiermee een methode in handen hadden waarmee ze dieper in het verleden konden kijken. De gedachte was dat bepaalde grammaticale eigenschappen van talen misschien minder snel veranderden dan de woordenschat.
Dunn zelf relativeert die hoge verwachtingen. "Wij onderzochten in 2005 een groep van 31 talen die ten oosten van Nieuw-Guinea, op een groep eilanden in de Stille Oceaan, werden gesproken. Het vergelijken van de woordenschat leverde daar niet zoveel op. Toen hebben we het op deze manier geprobeerd, dus op basis van grammaticale profielen, en daar kwam een mooie en heel plausibele stamboom van talen uit.
Er zijn gebieden in de wereld waar dit veel minder goed zou uitpakken, omdat de grammatica van talen daar veel sneller is veranderd. De snelheid waarmee talen veranderen en hoé ze veranderen, is namelijk absoluut niet constant. Soms gaat het snel, soms langzaam. Soms zijn het vooral de woorden die veranderen, soms is het vooral de grammatica." Het Surinaams (Sranantongo) bijvoorbeeld is in de koloniale tijd uit het Engels ontstaan. Dat kun je nog heel goed aan de woordenschat zien, maar nauwelijks nog aan de grammatica. En omgekeerd zijn er bijvoorbeeld in Nieuw-Guinea veel talen die grammaticaal sterk op elkaar lijken, maar totaal andere woordenschatten hebben.
Verhaal
Er wordt al twee eeuwen lang gezocht naar taalverwantschappen en taalfamilies. Duizenden taalwetenschappers hebben zich er her en der, op alle continenten, mee beziggehouden. Je zou je kunnen afvragen: Waar doen ze toch al die moeite voor? Wat maakt het uit of talen familie van elkaar zijn, en wat maakt het uit of ze nabije familie zijn van elkaar dan wel verre familie?
Het belangrijkste antwoord op die vraag is: behalve dat ze inzicht bieden in talen en hoe die zich gedragen, vertellen taalfamilies iets over de geschiedenis. Over hoe mensen en culturen zich in het verleden hebben verspreid. Het mooiste voorbeeld daarvan is de Austronesische taalfamilie. De Austronesische talen, waarvan er zo'n 1200 bestaan, hebben zich vanuit Oost-Azië verspreid over de grote en kleinere eilanden van Zuidoost-Azië en de Stille Oceaan. Aan de hand van
de stamboom van die talen kun je heel mooi zien hoe die eilanden geleidelijk door de mens gekoloniseerd zijn.
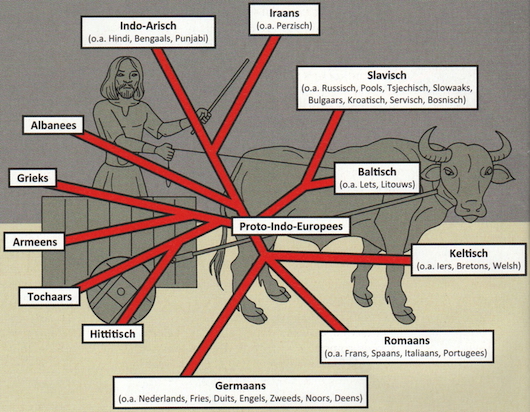
De stamboom van de Indo-Europese taalfamilie
Dichter bij huis is er het overduidelijke voorbeeld van de Romaanse talen. Die vertellen uiteraard iets over de eeuwenlange invloed van het Romeinse Rijk. Gaan we hier in Europa verder terug in de geschiedenis, dan wordt het verhaal dat de taalfamilies vertellen al wat minder duidelijk. De Germaanse talen zouden ontstaan zijn uit het Oergermaans, dat ooit in Noord-Duitsland en Zuid-Scandinavië werd gesproken. Welk verhaal zit er achter de verspreiding van het Germaans? Was dat vooral migratie (mensen die zich verplaatsten) of was dat vooral ook een kwestie van culturele invloed: superieure technologie die mensen van elkaar overnamen, of de verspreiding van een bepaalde godsdienst? En het Germaans behoort weer tot die grotere taalfamilie van de Indo-Europese talen, die zich uitstrekt van Ierland (Keltisch) tot diep in Iran (Perzisch) en India (Sanskriet). Ook daar zit een geschiedenis aan vast. Maar welke?
Het 'proto-Indo-Europees', de (denkbeeldige) taal waar al die huidige talen uit voortgekomen zouden zijn, zou volgens sommigen ooit ergens in het steppegebied van Oost-Oekraïne, Zuid-Rusland en West-Kazachstan gesproken zijn, door semi-nomaden die over paarden beschikten en zich daarmee hebben verspreid over Europa en Azië. Dat is één theorie. Een andere theorie houdt het erop dat dit 'oer-Indo-Europees' ooit in Anatolië (Noord-Turkije dus) werd gesproken, door vroege landbouwers: hun landbouwcultuur zou zich langzaam over Europa en Azië hebben uitgebreid.
Anatolië?
De manier waarop talen zich verspreiden, kun je volgens Michael Dunn ook wel een beetje vergelijken met de manier waarop virussen dat doen. Een groep taalwetenschappers kwam op het idee om computerprogramma's die normaal op virussen worden toegepast, voor de verandering eens los te laten op de Indo-Europese talen - op informatie over 103 talen, om precies te zijn. Daarbij werden wederom die uit nullen en enen opgebouwde profielen gebruikt - in dit geval verwezen de nullen en enen naar het al dan niet voorkomen van bepaalde cognaten in die talen.
Bovendien is van a1 die talen bekend waar ze gesproken worden, of, in het geval van uitgestorven talen zoals het Latijn en het Hittitisch, waar en wanneer ze werden gesproken. Als je die informatie combineert met de stamboom die de computer berekent, dan kun je, net als bij virussen, uitrekenen waar het ooit allemaal is begonnen: de plaats en tijd van de linguistische 'virusuitbraak'. De software wees Anatolië aan als de meest waarschijnlijke bakermat van het Indo-Europees.
Dunn: "Het is leuk om dit juist voor de Indo-Europese talen te doen, omdat de discussie daar gaat over twee met elkaar rivaliserende theorieën, die allebei zeer tot de verbeelding spreken. Is de verspreiding van het Indo-Europees het gevolg van oprukkende seminomaden te paard, of heeft het eerder te maken met de geleidelijke verspreiding van een landbouwcultuur vanuit Anatolië?"
Taalwetenschappers die niet in die Anatolië-theorie geloven - en dat zijn er nogal wat - zijn nu door Dunn en de zijnen uitgenodigd om zelf met de data en de software te stoeien. "Zij bekijken of er correcties nodig zijn in de data en hebben ook data van een aantal vrij obscure, uitgestorven talen toegevoegd. Daarna laten we er de software opnieuw op los." Het laatste woord is hier dus nog niet over gezegd.
Bron: Onze Taal, 83ste jaargang, december 2014, blz. 336
terug naar het literatuuroverzicht
terug naar het weblog
^